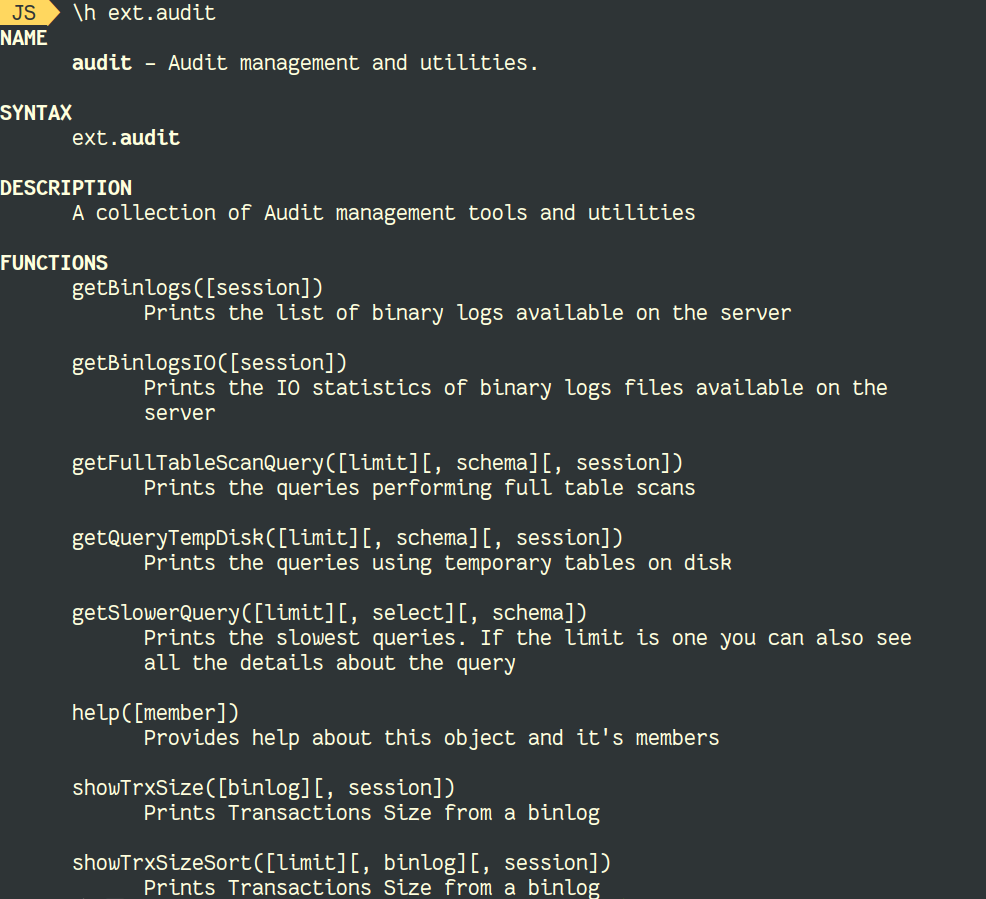
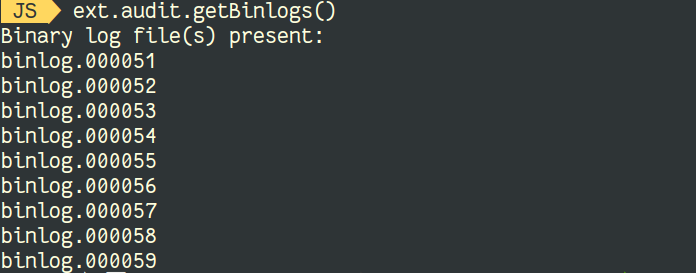
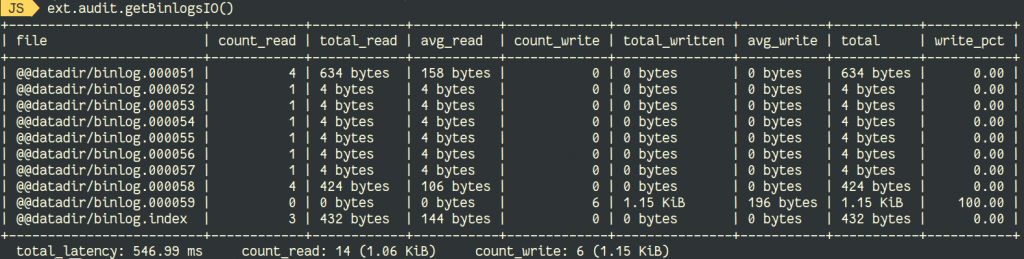
MySQL supports different types of Indexes. They depend on the storage engine and on the type of data. This is the list of supported indexes:
- B-trees (the most common)
- R-trees (for spatial data)
- Hashes (for Memory engine)
- Inverted (for InnoDB Full Text)
Best Practices
My recommendation are valid for InnoDB storage engine. I won’t talk about MyISAM. There are some best practices to follow when designing your tables. These are the 3 most important:
- use a good Primary Key
- don’t include the Primary Key as the right most column of the index, it’s always there anyway (hidden)
- remove not used indexes
InnoDB and a good Primary Key
Primary Key selection in InnoDB is very important. Indeed, InnoDB tablew storage is organized based on the values of the primary key columns, to speed up queries and sorts involving the primary key columns. For best performance, choose the primary key columns carefully based on the most performance-critical queries. Because modifying the columns of the clustered index is an expensive operation, choose primary columns that are rarely or never updated.
Also it’s very important to avoid “rebalancing” the cluster index at each write. This is why a sequential value is recommended as Primary Key.
Let’s compare a table using a sequential Primary Key (integer auto_increment) and a table using a completely random Primary Key. We will check how many pages are touched. To do so we check the LSN (bigger number are latest touched page):
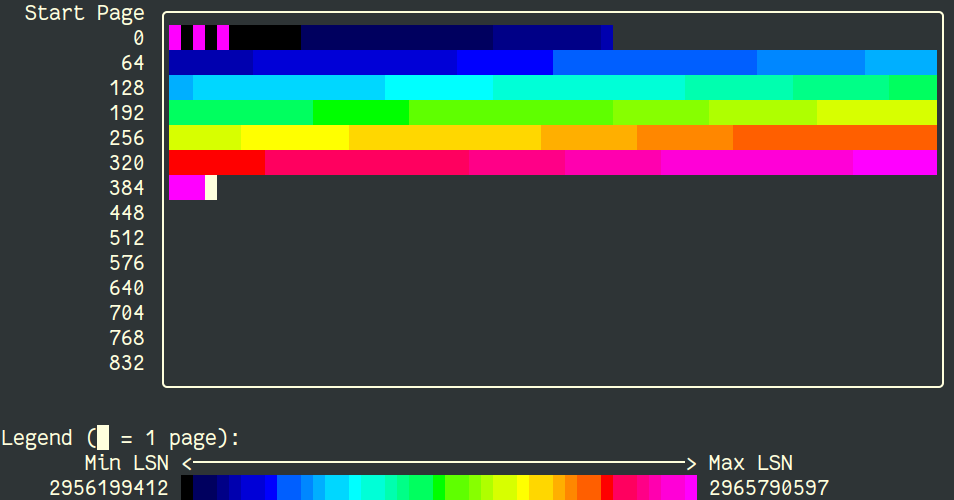
id int auto_increment primary keyWe can see that new records are added at the end of the table space.
Now let’s see what happens in the opposite case:

pk varchar(255) NOT NULL primary keyIt’s obvious that every time a new record is inserted, InnoDB has to place it in order and must move all the pages to have it sorted. This is the “clustered index rebalancing” that you should avoid at any cost ! Imagine the effect of that on a table of serveral hundreds of Gigabytes !!
Additionally, it’s also important to not have the Primary Key included in any secondary index as the right most column.
Secondary indexes (if the returned value is not part of it) are used to lookup the matching values using the index and then retrieve the full record through a second lookup using the clustered index. So 2 lookups are required when using secondary indexes if data not included in the index is required.
To perform such second lookup, every secondary index contains already the value of the primary key. The value is hidden.
This means that if you have a table like this:
+----------+-------------+------+-----+-------------------+-------------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+-------------------+-------------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(20) | YES | | NULL | | | inserted | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED | +----------+-------------+------+-----+-------------------+-------------------+
Let’s imagine you would like to create an index including name and id, the definition would be:
alter table secondary add index new_idx(name, id);
But in reality the index will be new_idx(name, id, id)
A correct index definition would be then to have just new_idx(name).
Now that you know Primay Keys are always included “for free” to any secondary index, you can imagine the consequence of having a PK on a varchar(255) in utf8 ! Such Primary Key will add 1022 bytes to every secondary index entries you would create !
And what about no Primary Key ?
Would it be better to have no Primary Key then ?
The usual answer by every DBA is “it depends !”
Usually I would recommend to always define a Primary Key.
Now if you have only one single table in MySQL that doesn’t have Primary Key and that you don’t intend to use Group Replication (it’s mandatory to have a Primary Key defined for every table to allow certification!), it might be better for performance to have no primary key then a bad one !
However, you should not have multiple tables without Primary Keys or you may encounter scalability issues.
If you don’t define a Primary Key, InnoDB will use the first non NULL unique key as Primary Key. If your table doesn’t have any unique key not NULL, then InnoDB will generate a sequential hidden Primary Key stored on 6 bytes. This hidden clustered index is calledGEN_CLUST_INDEX . But this Primary Key incremented value is shared by all InnoDB tables without Primary Key !
This means if you have 10 tables without Primary Key, if you do concurrent writes on each of them, you will have to wait for mutex contention on that counter.
Stay tuned for the next article on MySQL and Indexes.